本文介绍 Java 的 3 种 IO 模型
何为 I/O?
I/O 描述了计算机系统与外部设备之间的通信过程。用户进程需要执行 IO 操作的话,需要通过系统调用来访问内核空间,即具体 IO 的执行由操作系统的内核来完成。
平常接触最多的是磁盘 IO(读写文件)和网络 IO(网络请求和响应)
当程序发起 I/O 调用后,会经历两个步骤:
- 内核等待 I/O 设备准备好数据
- 内核将数据从内核空间拷贝到用户空间
UNIX 系统下, IO 模型一共有 5 种:同步阻塞 I/O、同步非阻塞 I/O、I/O 多路复用、信号驱动 I/O 和异步 I/O。
- 同步非阻塞 I/O:一直调用 read 请求数据,如果没有数据会直接返回,直到数据准备好了。在等待数据过程中,会频繁在用户态和内核态之间切换。
Java 中 3 种常见的 IO 模型
BIO
BIO 属于同步阻塞 IO 模型
同步阻塞 IO 模型中,应用进程在发起 IO 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。

stream 相关的 API 都是阻塞的
NIO
NIO 是支持面向缓冲的,基于通道的 IO 操作方法。Java 中的 NIO 是 I/O 多路复用模型。

IO 多路复用模型中,线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间 -> 用户空间)还是阻塞的。
IO 多路复用模型,减少无用的系统调用,降低了对 CPU 资源的消耗。
目前支持 IO 多路复用的系统调用,有 select,epoll 等等。select 系统调用,目前几乎在所有的操作系统上都有支持。
- select 调用:内核提供的系统调用,它支持一次查询多个系统调用的可用状态。几乎所有的操作系统都支持。
- epoll 调用:linux 2.6 内核,属于 select 调用的增强版本,优化了 IO 的执行效率。
使用 NIO 不一定意味着高性能,其性能优势体现在高并发和高延迟的网络环境下。当连接数较少、并发程度较低或者网络传输速度较快时,NIO 的性能并不一定优于传统的 BIO。
三大组件
三大组件包括 Channel、Buffer、Selector
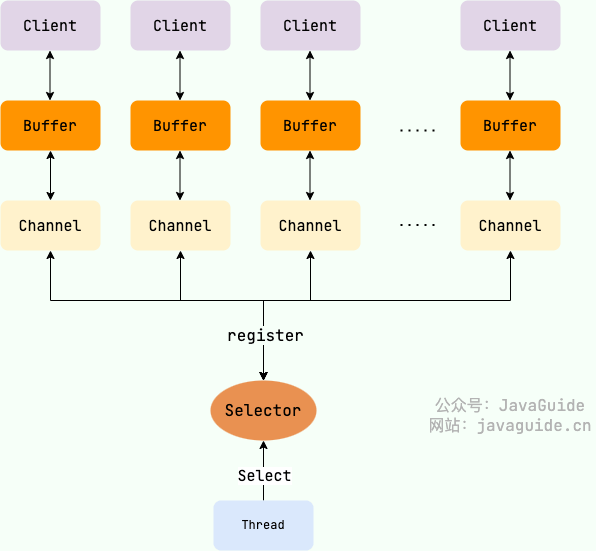
Channel
用于读写数据的双向通道,可以从 channel 中读取数据到 buffer,也可以将 buffer 的数据写入 channel。
常用的 Channel 有:
FileChannel:文件传输通道DatagramChannel:UDP 传输通道SocketChannel、ServerSocketChannel:TCP 传输通道
Buffer
用于缓冲读写数据,常用的是 ByteBuffer
ByteBuffer 食用示例:
1 | try (FileChannel channel = |
Buffer 结构
Buffer 中有三个重要的属性:capacity、position、limit。有两种模式:读模式和写模式。Buffer 被创建之后默认是写模式,调用 flip() 可以切换到读模式。如果要再次切换回写模式,可以调用 clear() 或者 compact() 方法。
默认状态:
写入 4 个字节的状态:
调用 flip() 方法,position 移到读取位置,limit 切换到读取限制:
调用 clear() ,回到默认状态;调用 compact(),把未读完的向前移,切换到写模式:
Seletor
用来配合一个线程管理多个 Channel,获取这些 Channel 上发生的事件。
一个多路复用器 Selector 可以同时轮询多个 Channel,底层 JDK 使用了 epoll() 调用。
在注册 Channel 到 Selector 上时,同时需要 Channel 添加独立的 Buffer。将 Channel 注册到 Selector 上,会返回一个 SelectionKey,用来标识某个 Channel,并且会监听该 Channel 上的事件,如 accept、connect、read、write。不同类型的 Channel 关注的事件不同,需要给 SelectionKey 绑定关注的事件。当没有事件发生时,线程会阻塞。
select 方法,没有事件发生时线程阻塞,有事件发生才会恢复运行。在事件未处理时,线程不会阻塞,因此事件要么处理,要么取消,否则线程会陷入死循环。
selector 在事件发生后,会向 selectedKeys 集合中加入对应的 key,但不会主动删除,因此处理完某个 key 应该主动移除,防止 NPE。因为涉及到删除操作,应该使用迭代器遍历
零拷贝
零拷贝是指计算机执行 IO 操作时,CPU 不需要将数据从一个存储区域复制到另一个存储区域,从而可以减少上下文切换以及 CPU 的拷贝时间。
传统的 IO 问题
假设我们现在需要将一个文件通过 socket 写出,伪代码如下:
1 | File f = new File("data.txt"); |
内部的工作流程如下图:

- 调用 read 方法后,程序会从用户态切换到内核态,由内核将数据读到内核缓冲区,这时候用户线程阻塞,CPU 不参与
- 从内核态切换会用户态,将数据从内核缓冲区拷贝到用户缓冲区(即buf),此时 CPU 参与拷贝
- 将数据从用户缓冲区写入 socket 缓冲区,CPU 参与拷贝
- 从用户态切换到内核态,调用内核将 socket 缓冲区中的数据写入网卡,CPU 不参与
以上过程经历 4 次上下文的切换和 4 次数据拷贝
mmap 优化

使用内存映射,将堆外内存映射到 JVM 内存,减少了一次数据的拷贝。用户态与内核态的切换次数没有减少
- 堆外内存不受 GC 的影响,因此内存地址固定,有助于IO 读写
- java 中的
DirectByteBuf对象仅维护了此内存的虚引用,内存回收分成两步DirectByteBuf对象被垃圾回收,将虚引用加入引用队列- 通过专门线程访问引用队列,根据虚引用释放堆外内存
sendFile 优化

将数据读到内核缓冲区后,无需切换回 Java,直接可以将数据复制到 socket 缓冲区,数据拷贝了 3 次,上下文切换 2 次
- Java 调用
transferTo方法后,从用户态切换至内核态,使用 DMA 将数据读入内核缓冲区,不会使用 cpu - 数据从内核缓冲区传输到 socket 缓冲区,cpu 会参与拷贝
- 最后使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 cpu
sendFile + DMA gather copy

将数据读到内核缓冲区后,通过 DMA 直接将数据发送到网卡,整个过程不需要 CPU 的参与,数据拷贝了 2 次,上下文切换 2 次。
- Java 调用
transferTo方法后,从用户态切换至内核态,使用 DMA 将数据读入内核缓冲区,不会使用 cpu - 只会将一些 offset 和 length 信息拷入 socket 缓冲区,几乎无消耗
- 使用 DMA 将内核缓冲区的数据写入网卡,不会使用 cpu
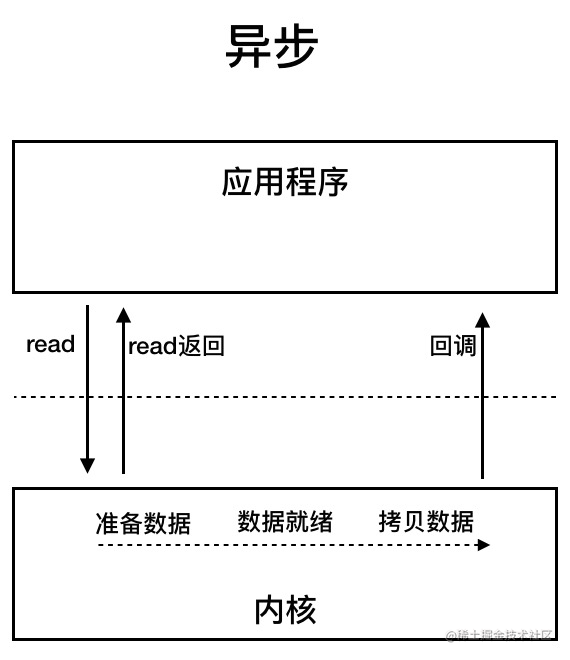
AIO
AIO 即 NIO2,是异步 IO 模型
异步 IO 是基于事件和回调机制实现。应用操作之后会直接返回,不会造成阻塞,当后台处理完成后操作系统会通知响应的线程进行后续操作